Building Block of Semantic Processing: Interpret the meaning of the text

December 20, 2023

In this post, we will understand the concept of how the field of NLP is attempting to make machines understand language like we humans do. We will understand different techniques that make this challenging task possible. This area is quite heavy on research and a lot of new advancements are happening in the field.
Let us start understanding terms and concepts which are fundamentals to understand the meaning of text like we humans do.
Terms and Concepts
To make computers understand the language, the very first topic that we have to understand is called terms and concepts. Let us take an example of objects that exist but we cannot touch, see, or hear them. A few examples include independence, freedom, algebra, and so on. But they still do exist and occur in natural language. We refer to these objects as 'concepts'. The whole way in which we understand something is in terms of concept and 'meaning' is constructed based on the concept.
Another example of this concept is a cat. When we see a cat we have a concept in the mind that what constitutes a cat. Like a cat has one tail, 4 feet, etc. But let's say if we see a cat without a tail, we still recognize it as a cat. That means even if some amount of data is missing we still can recognize but on the other hand if we see a cat sitting in class and taking notes we will fail to recognize it as a cat. This is because there is some kind of notion attached that defines the concept of a cat.
The 'terms' act as handles to 'concepts', and the notion of ‘concepts’ gives us a way to represent the ‘meaning’ of a given text. In other terms, a concept is an abstract idea or general notion that is derived from experience, reasoning, or imagination whereas a term is a word, phrase, or symbol that represents a concept.
Concepts are generally hard to experience or are purely latent such as ownership, prime numbers, freedom, passion, etc. but some concepts have sensory experiences associated with them such as cats.
Now the question comes, how do terms acquire certain concepts?
The context in which terms are frequently used makes the term acquire a certain meaning. For example, the word ‘bank’ has different meanings in the phrases ‘bank of a river’ and ‘a commercial bank’ because the word happens to be used differently in these contexts. Therefore, the word 'bank' acquires a concept based on the context the word is used.
Distributional Hypothesis
As we have seen above, the association between the term and concept is not static and it keeps on involving. The meaning that a particular word acquires is not the property of the word itself but a property of how the word is used in different contexts. This is what is called Ordinary Language Philosophy (OLP) which states that the association of terms to concepts is not static and emerges through use.
The Ordinary Language Philosophy also sometimes called the distributional hypothesis can be stated in different ways. One way to state is that the words that are used in similar contexts tend to have similar meanings. Another way to state the same hypothesis is that a word is known by the company it keeps i.e., based on the accompanying words for the given word we can try to establish the meaning of the word.
Refer to the post, Distributional Semantics | Techniques to represent words as vectors to uncover the details about how we can use word vectors to understand the context in which a word is used.
Entity and Entity Types
To further refine the representation of the 'meaning' of the word let us understand entity and entity types. In the contextual world, we see entity types and in the physical world, we see entities. Further, multiple entity types can be grouped under a concept. Refer to the diagram shown below.

Entities of similar types are grouped into what is known as an entity type. From entity type, we can drive multiple concepts. The interface with which the conceptual world interacts with the physical world is called entity type.
You can see above that we are using a hierarchical model of concepts, entities, and entity types to answer some real-world questions and process the 'meaning' of sentences.
Associations Between Entity Types
To understand the association between the entity types, let us consider an example. For Smart assistant to answer the questions like 'What is a Labrador?' To answer this, it needs mapping between entities and entity types, i.e. it needs to understand that a Labrador is a dog, a mammal is an animal, etc.
To achieve the above task we need to develop associations between entities and entity types. And, these associations are represented using the notion of predicates. Let’s understand the idea of predicates.
Predicates
The association (or semantic association) between entities and entity types is represented using the notion of predicates. Predicate gives a simple model to process the meaning of complex statements.
For example, say we ask an artificial NLP system - "Did France win the football World Cup final in 2018?". The statement can be broken down into a set of predicates, each returning True or False, such as win(France, final) = True, final(FIFA, 2018) = True.
A predicate is a function that takes in some parameters and returns True or False depending on the relationship between the parameters. For example, a predicate teacher_teaches_course(P = professor Srinath, C = text analytics) returns True.
Processing the meaning of the sentence involves understanding the associations between entities. For example "A football team is comprised of 11 players" is an example of relation type = 1 (since there is only one entity type - football players), though the relationship instance is 11 (since there are 11 instances of the entity).
Let us consider an example sentence "Shyam supplies cotton to Vivek which he uses to manufacture t-shirts" and represent the sentence using the notion of predicates. One of the binary predicates of the sentence can be supplier_manufacturer(Shyam, Vivek), which returns True or False.
Most real-world phenomena are much more complex to be represented by simple binary predicates. So we need to use higher-order predicates (such as the ternary predicate supplier_manufacturer_product(Shyam, Vivek, t-shirts)). Further, if a binary predicate is true higher-order predicate doesn't need to also be true. Let us draw a semantic association diagram to understand the same.
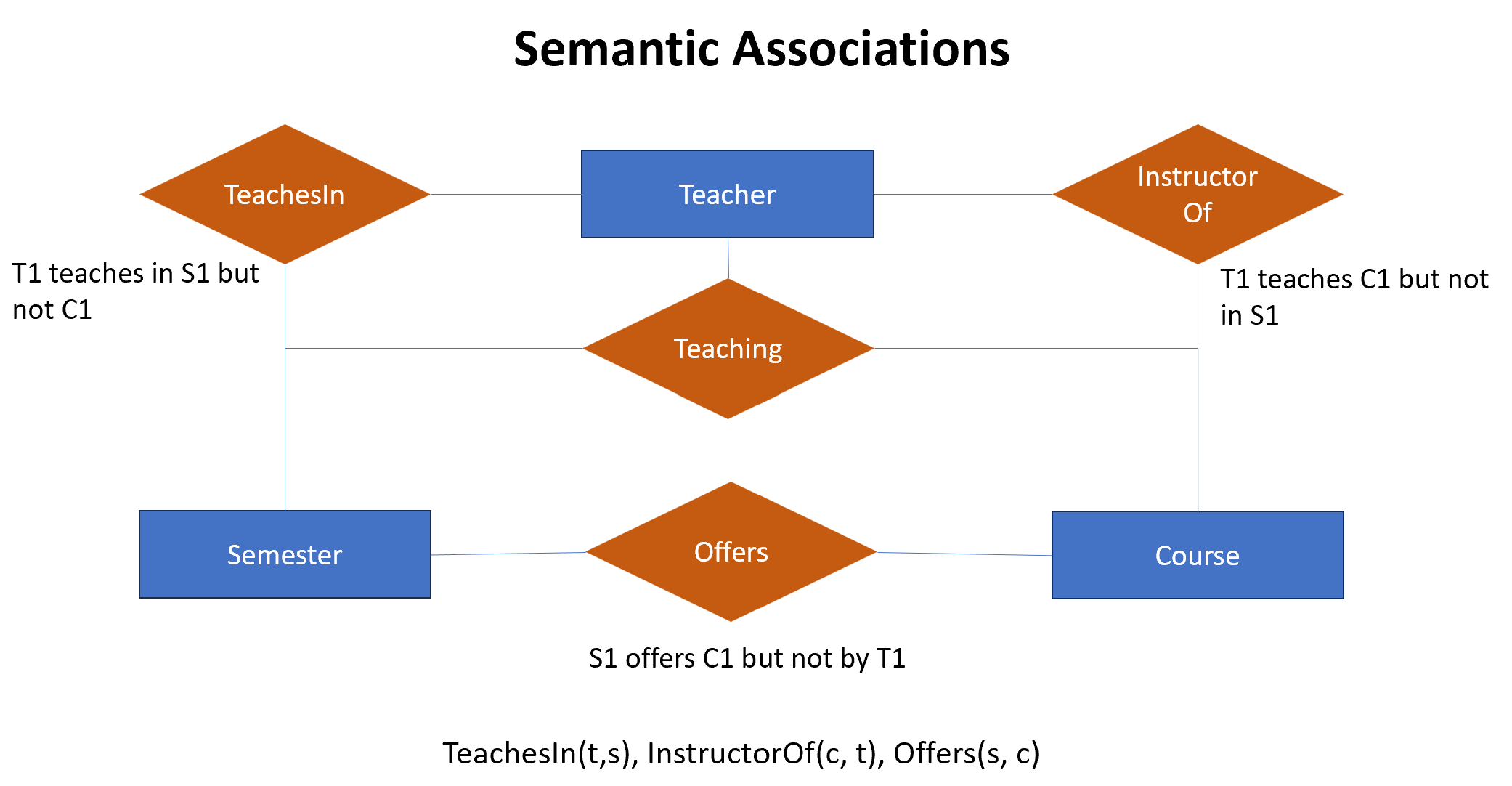
In the diagram shown above, the semantic associations are represented as predicates or relationship types that relate to one or more entity types. Where, 'teaching' is ternary predicate teaching(teacher, semester, course) and this is true only if teacher T1, teaches the course C1 in semester S1. If we break this down into binary predicates we get three predicates TeachesIn(teacher, semester), InstructorOf(teacher, course), and offers(course, semester).
But we can see clearly in the diagram above that, there is a possibility that these binary predicates are true but the ternary predicate is still not true. This means, that even if all the binary relationships of a ternary relationship are true, it still does not imply that the ternary relationship will also be true. This implies that, in general, we cannot simply break down complex sentences (i.e. higher-order predicates) into multiple lower-order predicates and verify their truth by verifying the lower-order predicates individually.
Arity and Reification
The arity of the predicate is defined as the number of parameters that predicates take. The arity of the predicate is important, as the richer the arity better the semantic association. The arity of a predicate is the number of arguments or inputs that the predicate takes. For example, R(x,y,z) is a relation of arity = 3.
For practical semantic association, we usually work with a maximum arity of 2 as higher-order predicates (i.e. having a large number of entity types as parameters) are complex to deal with. Resource Description Framework (RDF) which we will see in the next section is also represented as a binary predicate. However, we have seen in our earlier example that binary predicates are not able to capture complex sentences. So how do we deal with this problem?
To solve this problem, we use a concept called reification. Let's understand the concept of reification next.
Reification refers to combining multiple entity types to convert them into lower-order predicates. The reified entity is a virtual entity. Therefore using reification, we can convert higher-order relationships into binary relationships.
For example, India is a country. What does India mean? Does India mean people who live there, culture, festivals, food, etc. it means everything. All the entities are abstracted in the country of India. Another example can be, "Make in India" which is a virtual entity, that represents a combination of many things.
Further, every hashtag on social media is a form of reification. Consider the following tweet: 'As a reminder I have to admit there are benefits to #Brexit which I never ever knew about". here if #Brexit is not just one thing but instead if we search entire social media on the #Brexit hashtag, we will be getting all the tweets related to the topic.
Therefore, using the concept of reification we can model higher-order predicates as a binary predicate.
Example of Binary Predicate: Resource Description Framework (RDF)
One such framework that can help describe resources on the web is called resource description framework (RDF). It is designed to be read and understood by computers and help understand the meaning of the web pages or in other words describe the information about web pages.
The RDF triple forms the basic building block of linked open data (semantic web). It represents the binary association in the form of (subject, predicate, and object). The Resource Description Framework (RDF) is a framework for representing information (or semantics) on the Web. Example RDF using XML language is as shown below:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:si="https://www.techladder.in.com/rdf/">
<rdf:Description rdf:about="https://www.techladder.in">
<si:title>Tech Ladder</si:title>
<si:author>Tavish Aggarwal</si:author>
</rdf:Description>
</rdf:RDF>The RDF language is a part of the W3C's Semantic Web Activity. W3C's "Semantic Web Vision" is a future where web information has an exact meaning, web information can be understood and processed by computers, and computers can integrate information from the web.
There are certain extensions of RDF which is called NQUAD standard which is an extension of RDF triple. It represents the binary association along with the context in the form (subject, predicate, object, context).
Next, let's understand an example of a huge knowledge graph called schema.org to create a schema for a wide variety of entities (and reified entities) in one structured schema.
Schema
To perform semantic processing or to understand the meaning of the sentence we need a framework to interpret the data. We need a structure using which we can represent the meaning of sentences. One such schematic structure (used widely by search engines to index web pages) is schema.org.
Schema.org is a joint effort by Google, Yahoo, Bing, and Yandex (Russian search engine) to create a large schema relating to the most commonly occurring entities on web pages. The main purpose of the schema is to ease search engine querying and improve search performance.
For example, say a web page of a hotel (for example Hotel Ginger) contains the words 'Ginger' and 'four stars'. How would a search engine indexing this page know whether the word 'Ginger' refers to the plant ginger or Hotel Ginger? Similarly, how would it know whether the phrase 'four stars' refers to the rating of a hotel or to astronomical stars?
To solve this problem, schema.org provides a way to explicitly specify the types of entities on web pages. For example, one can explicitly mention that 'Ginger' is the name of the hotel and specify various entities such as its rating, price, etc. as shown in the example below.
The attributes itemtype='Hotel' and itemprop='name', 'rating', and 'price' explicitly mention that the text on the web page (in the section inside the <div>) is about a hotel, that the hotel's name is Ginger, its rating is four stars and the price is INR 3500.
<div itemscope itemtype ="http://schema.org/Hotel">
<h1 itemprop="name">Ginger</h1>
<span>Rating: <span itemprop="rating">Four Star Hotel</span>
<span itemprop="price">INR 3500</span>
</div>Associations between a wide range of entities are stored in a structured way in gigantic knowledge graphs or schemas such as schema.org.
Semantic Associations
From our earlier discussion, we have an understanding that the entities have associations. However, there could be different types of associations depending on the application. There are a few generic associations that are there as demonstrated below:
- IS-A: Represents superclass-subclass relationship. "B is-a A" implies that every B is a type of A. For example, a cat is a mammal. But Cats can have certain properties that mammals don't have.
- IS-IN: Represents a container-part relationship. "B is-in A" implies that if A is inaccessible then so is B. For example, my wallet is in my car. If the car is not reachable so does the wallet.
In addition to knowing the two types of semantic association of the sentence we also have an interest to know about the 'aboutness' of the sentence which is the third type of semantic association.
The concept of aboutness is related to topic modeling which in itself is an extensive discussion. To know more about it, refer to the post, Diving Deep into Topic Modeling: Understanding and Applying NLP's Powerful Tool.
Moving forward, as we have gone through the terms and concepts; let's understand the five kinds of relationships/associations between terms and concepts can be grouped into as shown below:
- Hypernyms and hyponyms: This shows the relationship between a generic term (hypernym) and a specific instance of it (hyponym). For example, the term ‘Punjab National Bank’ is a hyponym of the generic term ‘bank’.
- Antonyms: Words that are opposite in meanings are said to be antonyms of each other. Example hot and cold, black and white, etc.
- Meronyms and Holonyms: The term ‘A’ is said to be a holonym of the term ‘B’ if ‘B is part of ‘A’ (while the term ‘B’ is said to be a meronym of the term ‘A’). For example, an operating system is part of a computer. Here, ‘computer’ is the holonym of ‘operating system’ whereas ‘operating system’ is the meronym of ‘computer.
- Synonyms: Terms that have a similar meaning are synonyms of each other. For example, ‘glad’ and ‘happy’.
- Homonymy and polysemy: Words having different meanings but the same spelling and pronunciations are called homonyms. For example, the word ‘bark’ in ‘dog’s bark’ is a homonym to the word ‘bark’ in ‘bark of a tree’. Polysemy is when a word has multiple (entirely different) meanings. For example, consider the word 'pupil'. It can either refer to students or eye pupils, depending upon the context in which it is used.
Even after defining such a wide range of association types, we have still not covered the wide range of complexities of natural languages. For example, consider how two words are often put together to form the phrase ‘cake walk’. The semantics or concept of the combination of these words could be very different than the individual words. i.e., the meanings of the terms 'cake' and 'walk' are very different from the meaning of their combination.
Such cases are said to violate the principle of compositionally. Let us understand what we mean by this.
Principle of Compositionality
When two words representing specific concepts are combined, in the sense of their concepts, the combined phrase may or may not represent the composition of the constituent concepts.
Example words where the composition of combining two words is retained include red ball, heavy bag, round cake, etc. But there are words when combined lose the composition. This includes red handed, heavy duty, round table, etc. Collocations represent phrases, where the combined meaning is the sum of the meaning of its constituent parts, plus an extra dimension that cannot be predicted from the meaning of the parts.
The principle of compositionally although valid in most cases, is often violated as well. This is an important insight to understand the nature of semantics and also develop algorithms for semantic processing.
Databases - WordNet and ConceptNet
To handle such complexity of the natural language there are two main databases designed that can help understand the meaning of the text. Let's understand them in detail and start with WordNet.
WordNet is a semantically oriented dictionary of English, similar to a traditional thesaurus but with a richer structure. It is a lexical database for the English language which is useful for semantic processing. Such kind of open source database comes in handy because of the complexities of the words and their having multiple meanings in the context we use them.
WordNet groups words into cognitive synonyms called synsets, each representing different concepts. Each synset is interlinked using conceptual and lexical relations.
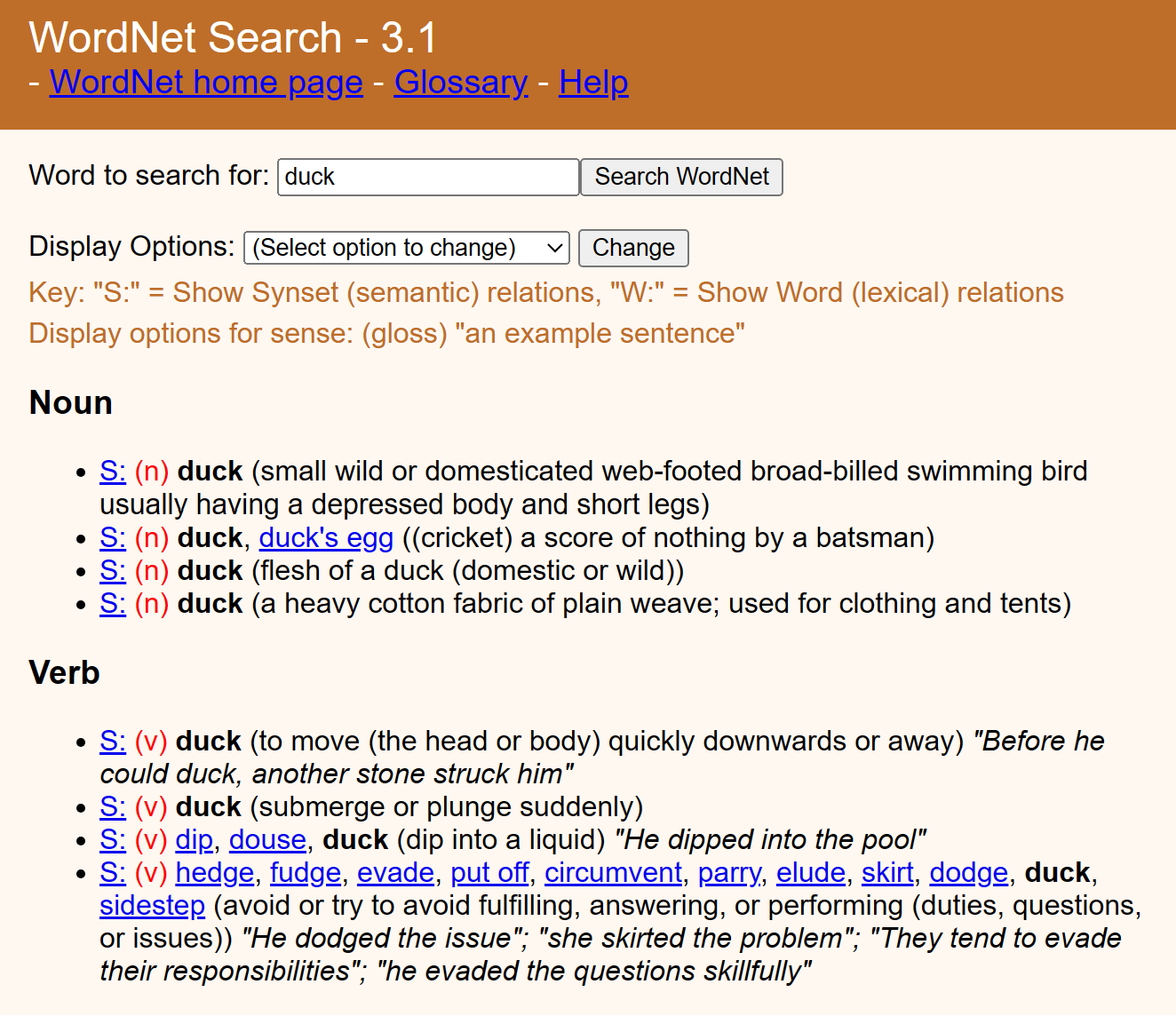
Different senses of the words are grouped into different synsets as shown in the example above for the word 'duck'. Refer to the WordNet site to explore on your own and play with multiple examples.
There is also a Python library 'textblob' available to get the sysnets of the words pragmatically. Let us look at the code:
from textblob import Word
word = Word("plant")
# Printing 5 synsets of word 'plant'
print(word.synsets[:5])
print(word.definitions[:5])
# Output
# [Synset('plant.n.01'),
# Synset('plant.n.02'),
# Synset('plant.n.03'),
# Synset('plant.n.04'),
# Synset('plant.v.01')]
# ['buildings for carrying on industrial labor',
# '(botany) a living organism lacking the power of locomotion',
# 'an actor situated in the audience whose acting is rehearsed but seems spontaneous to the audience',
# 'something planted secretly for discovery by another',
# 'put or set (seeds, seedlings, or plants) into the ground']Another important resource for semantic processing is ConceptNet which deals specifically with assertions between concepts. For example, there is the concept of a “dog”, and the concept of a “kennel”. As a human, we know that a dog lives inside a kennel. ConceptNet records that assertion with "/c/en/dog, /r/AtLocation, /c/en/kennel".
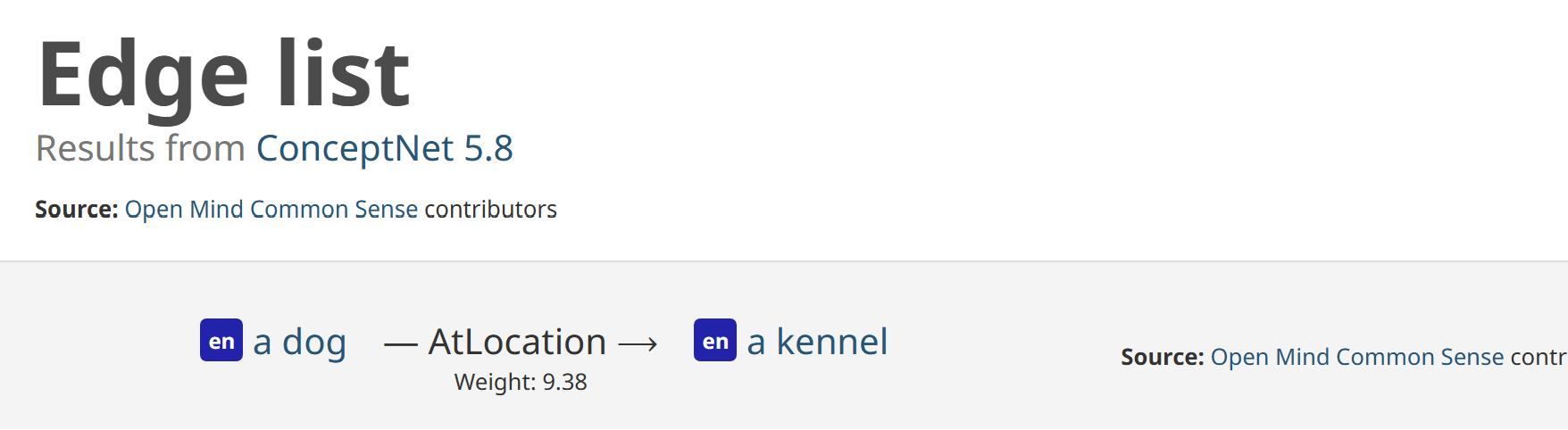
Refer to the ConceptNet site to explore on your own and play with multiple examples.
ConceptNet is a representation that provides commonsense linkages between words. For example, it states that bread is commonly found near toasters. These everyday facts could be useful if, we are building a smart chatbot that can respond “Since you like toasters, do also like bread? I can order some for you.”
But, unfortunately, ConceptNet isn’t organized as well as expected. For instance, it explicitly states that a toaster is related to an automobile. This is true since they are both mechanical machines, but if we are building chatbots we don't a chatbot to learn such kinds of relationships in most contexts.
Summary
With this, we have covered all the tools and concepts related to understanding the 'meaning' of the word or sentence. The post discusses the complexities of semantic processing in natural language understanding. And how one can use such tools for machines to understand the language like we humans do.
It covers concepts such as Ordinary Language Philosophy, Entity and Entity Types, Predicates, Arity and Reification, and the Principle of Compositionality. The post also explores the use of Resource Description Framework (RDF), Schema, and Semantic Associations.
The post further covers the use of the two most popular databases WordNet and ConceptNet in handling the complexities of words and their meanings in different contexts.
Author Info